Table of Contents
TLDR;
Using pandas (pip install pandas)
import pandas as pd
data = pd.read_csv("actors.csv").to_dict(orient="row")Code language: JavaScript (javascript)Using native csv.DictReader
import csv
with open("actors.csv") as f:
data = [r for r in csv.DictReader(f)]Code language: JavaScript (javascript)Reading as a List
Let’s say we have the following CSV file, named actors.csv. You can download this file here.
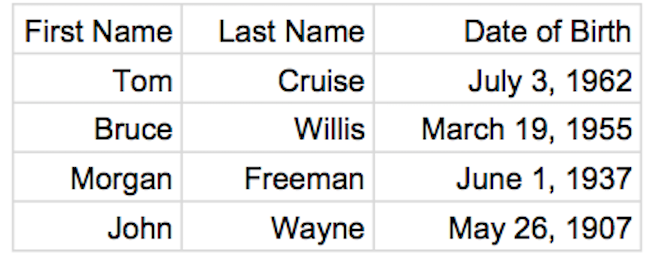
The first method demonstrated in Python docs would read the file as follows:
- Open the file
- Create a CSV reader
- Skip first line (header)
- For every line (row) in the file, do something
import csv
with open("actors.csv") as f:
reader = csv.reader(f)
next(reader) # skip header
data = []
for row in reader:
data.append(row)
Code language: PHP (php)This can be simplified a bit with list comprehension, replacing the for loop with [r for r in reader].
import csv
with open("actors.csv") as f:
reader = csv.reader(f)
next(reader) # skip header
data = [r for r in reader]
Code language: PHP (php)I am calling next(reader) to skip the header row (First Name, Last Name etc). Header MUST be removed, otherwise it will show up as one of the lists in your data. Header can also be removed via pop command, as follows:
with open("actors.csv") as f:
reader = csv.reader(f)
data = [r for r in reader]
data.pop(0) # remove header
Code language: PHP (php)Either of those will load the following data:
[
[
"Tom",
"Cruise",
"July 3, 1962"
],
[
"Bruce",
"Willis",
"March 19, 1955"
],
[
"Morgan",
"Freeman",
"June 1, 1937"
],
[
"John",
"Wayne",
"May 26, 1907"
]
]
Code language: JSON / JSON with Comments (json)The result will be a list of lists. We could get Tom’s name, for example, via data[0][0] command.
In [5]: data[0][0]
Out[5]: 'Tom'
Code language: JavaScript (javascript)Reading as a Dictionary
Python has another method for reading csv files – DictReader. As the name suggest, the result will be read as a dictionary, using the header row as keys and other rows as a values.
For example this:
import csv
with open("actors.csv") as f:
reader = csv.DictReader(f)
data = [r for r in reader]
Code language: JavaScript (javascript)Will result in a data dict looking as follows:
[
{
"First Name": "Tom",
"Last Name": "Cruise",
"Date of Birth": "July 3, 1962"
},
{
"First Name": "Bruce",
"Last Name": "Willis",
"Date of Birth": "March 19, 1955"
},
{
"First Name": "Morgan",
"Last Name": "Freeman",
"Date of Birth": "June 1, 1937"
},
{
"First Name": "John",
"Last Name": "Wayne",
"Date of Birth": "May 26, 1907"
}
]
Code language: JSON / JSON with Comments (json)With this approach, there is no need to worry about the header row. Most importantly now data can be accessed as follows:
In: data[0]['First Name']
Out: 'Tom'
Code language: JavaScript (javascript)Which is much more descriptive then just data[0][0].
Reading as a Named Tuple
The problem with dictionaries in Python, is that they cannot be access (unlike JavaScript) via the dot notation. For example in our earlier example we could not do data[0].first even if the row name was first. We have to do the full key in square brackets.
Often I prefer to load my CSV file as a list of named tuples.
Named tuple is a special construct that allows accessing values via the dot notation. For example:
from collections import namedtuple
# First param - name of "Class"
# Second param - all fields (keys) that will be supported, space separated
Person = namedtuple("Person", "name age")
person = Person("Tom", 55) # New Person
print(person.name) # Will print Tom
Code language: PHP (php)I can read most CSV files that I work with, as such:
with open("actors.csv") as f:
reader = csv.reader(f)
Data = namedtuple("Data", next(reader))
data = [Data(*r) for r in reader]
Code language: JavaScript (javascript)The one bit of magic here is Data(*r). The *r simply tells Python interpreter to pass every value in the list i.e. ["Tom", "Cruise", "July 3, 1962"] as a parameter. Equivalent to calling Data with Data("Tom", "Cruise", "July 3, 1962").
Unfortunately, in our example the code will fail, since our header labels cannot serve as valid keys for a named tuple.
Rules for valid keys can be found, here. Most notably every identifier (i.e. named tuple key or a variable) must follow this rule.
Identifiers can be a combination of letters in lowercase (a to z) or uppercase (A to Z) or digits (0 to 9) or an underscore (_)
I added a bit of logic to make keys in this example valid by replacing spaces with underscores. I also converted everything to lower case to make it a bit easier to type.
with open("actors.csv") as f:
reader = csv.reader(f)
top_row = next(reader)
top_row = [t.lower().split()) for t in top_row]
top_row = ["_".join(top_row)]
Data = namedtuple("Data", top_row)
data = [Data(*r) for r in reader]
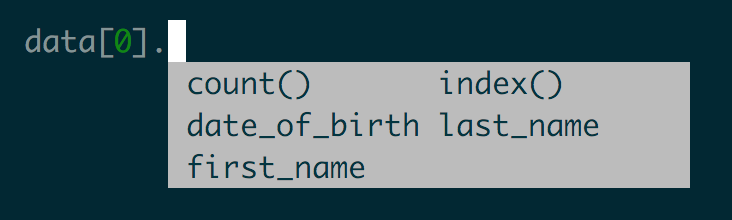
Code language: JavaScript (javascript)This may seem like a lot of extra work, but for me it’s worth it. I use iPython as my REPL (available via pip install ipython). Dot notation saves me a lot of time by removing the need to type [" "] for every key. In addition, iPython provides a helpful sugestion list after typing . and hitting the tab key.
Reading Using Pandas
Pandas is a very popular Data Analysis library for Python. It can be installed via pip install pandas. For a brief introduction to Pandas check out Crunching Honeypot IP Data with Pandas and Python.
Pandas makes it really easy to open CSV file and convert it to Dictionary, via:
import pandas as pd
data = pd.read_csv("actors.csv").to_dict(orient="row")
Code language: JavaScript (javascript)Please let me know in the comment area bellow if you have another preferred way of reading CSV files in Python.