Table of Contents
Part 1. A Naive Dream
The Dream
In late 2015, I finished reading Automate the Boring Stuff with Python and was very inspired to try to automate something in my life.
At the same time, I have been always fascinated by Mark Zuckerberg – the Bill Gates of our time. A lot of people love to hate on Mark, but I actually like the guy. Sure he got lucky in life, but at the same time he is doing something right for Facebook to continue to stay successful.
In any case, one day I had a “brilliant” idea. What if I write a script that would follow Mark’s public posts and send me a text whenever he posted something new? Then I can be the first guy to comment on his post.
After a while Mark would notice my comments and would begin to wonder “Who is this guy that is always posting meaningful responses to all of my posts?”. Then he would invite my wife and me to his house for dinner and our kids will become friends. 🙂
So, without further ado I got to work.
I’ve briefly considered using Facebook APIs to get notified on Mark’s posts. I’ve had mixed experience with APIs in the past, hitting rate limits pretty quick and other related problems. Plus, I wanted to use my Automate the Boring Stuff with Python knowledge 🙂
So I went the other route and wrote a Selenium script (which was really easy to do using selenium module in Python) that would:
- Log in to Facebook
- Use current timestamp as the time of last post
- Keep checking every 60 seconds if Mark has posted a new post
- Send me a Text using Twilio API, with a link to the new post
I happen to own a small server, so I set the script to run indefinitely in a headless browser (PhantomJS) and began to wait.
Paradise Lost
It took a couple of days for Mark to post something and I began to get worried that my script did not work.
At some point I had to go to the post office. Afterwards, I drove back home, parked my car, checked my phone and saw a new SMS text from my script. My heart started to beat really fast and I rushed to open the link. I soon realized that the post took place 5 minutes ago and I missed the notification when I was driving. By now the post already had thousands of comments…
Oh well, I thought, there is always the next time. Sure enough within a day I had another text. This time it was within under 1 minute from the original post. I quickly open the link, only to discover that Mark’s post already had close to 100 comments.
Now don’t get me wrong, I am not stupid. I knew that Mark’s posts were popular and would get a lot of comments.
I even tried to estimate, the rate at which people were posting replies. I’ve looked through Mark’s older posts and saw some posts with tens of thousands of comments. So if you take 10000 comments and divide by 24 hours, then divide by 60 minutes, you get about 7 posts per minute.
What I didn’t realize in my estimate is that those comments were not evenly distributed in time and that I had a very small chance of being the first to comment.
I knew that I was losing my dream and I considered my options 🙂
I could set my script to run more often than every 60 seconds, to give myself an early warning. By doing so I would risk showing up on Facebook’s radar as a spammer and it just didn’t feel right for me to bombard their servers.
Another option that I considered was to try to make an automated reply, in order to be one of the first people to comment. This approach, however, would defeat the purpose of saying something meaningful and would not help me to become friends with Mark.
I’ve decided against both of these ideas and admitted my defeat. I’ve also realized, that I could turn this (failed) experiment into an interesting Data Exploration project.
Part 2. Data Analysis
Scraping
Having made a big error in my estimate of the rate at which people were replying to Mark, I was curious to explore what and when people were saying. In order to do that, I needed a data set of comments.
Without putting much thought into it, I decided to scrape one of Mark’s most recent posts at the time.
Merry Christmas and happy holidays from Priscilla, Max, Beast and me! Seeing all the moments of joy and friendship…Posted by Mark Zuckerberg on Friday, December 25, 2015
My first approach was too try to modify my notification script to:
- Log in to Facebook
- Go to the post that Mark has made
- Click on “Show More Comments” link, until all comments were loaded
- Scrape and parse the HTML for comments
Once again I under estimated the scale of the operation. There were just too many comments (over 20,000) and it was too much for a browser to handle. Both Firefox and PhantomJS continued to crash without being able to load all of the comments.
I had to find another way
I proceeded to examine how View more comments requests were made using Network Toolbar in Chrome Developer Tools. Chrome allows you to right click on any request and to copy it as CURL via “Copy as cURL” option.
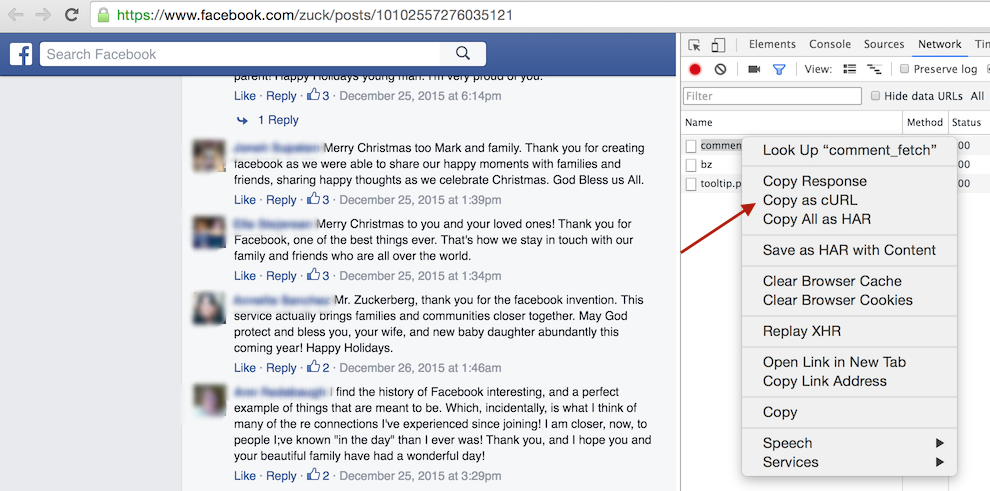
I’ve ran the resulting CURL command in my terminal, and it returned some JSON. BINGO!
At that point all I had to do was to figure out how pagination of comments was done. This turned out to be a simple variable in the query of the request, which acted as a pointer to the next set of comments to fetch.
I’ve converted the CURL command to a Python request code via this online tool.
After that I wrote a script that would:
- Start at pagination 0
- Make a comments request
- Store it in memory
- Increment the pagination
- Sleep for a random amount of time from 5 to 10 seconds
- Repeat the loop, until no more comments were found
- Save all of the comments to a JSON file
I’ve ended up with an 18Mb minimized JSON file, containing about 20,000 comments.
Analyzing the data
First I looked at the distribution of comments over time.
As can be seen in the two plots bellow, it looked a lot like exponential decay, with most of the comments being made in the first two hours.

First Two Hours
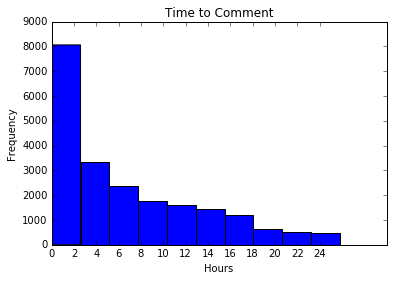
First 24 Hours
First 1500 comments were made within first 10 minutes. No wonder I had a hard time making it to the top.
Next I wanted to see what people were saying.
I created a word cloud of most commonly used keywords in comments using a python library called (surprise, surprise) – Word Cloud.

Looking at the word cloud I realized that I might have picked the wrong day to do this experiment. Most of the people responded in kind to Mark’s wishes of Merry Christmas and Happy New Year. That was great news for Mark, but kind of boring from the data exploration stand point.
Digging Deeper
After I finished the word cloud I’ve spent WAY TOO MUCH TIME trying to gain a deeper understanding of the data.
The data set turned out to be a bit too big for me to iterate on it quickly and all of the positive comments created too much noise.
I’ve decided to narrow down the data set by removing all comments with any of the following word stems. A word stem is simply a shortest version of the word that still makes sense. For example, by removing comments that have a word thank in it, I was able to remove both the comments with the words thank you as well as the comments with the word thanks. I’ve used nltk library to help me convert my words to stems.
I’ve organized the stems by a type of comment that they usually belonged to:
- Happy New Year Wishes
- new
- happ
- year
- wish
- bless
- congrat
- good luck
- same
- best
- hope
- you too
- Comment on Photo of the Family
- photo
- baby
- babi
- beautiful
- pic
- max
- family
- famy
- cute
- child
- love
- nice
- daughter
- sweet
- Thanking Mark for creating Facebook
- thank
- connect
- help
After removing all of the typical comments, I’ve ended up with 2887 “unusual” comments.
Digging Even Deeper
I’ve also recently finished reading Data Smart, from which I learned that Network Analysis can be used to identify various data points that belong together, also known as clusters.
One of the examples in the book used Gephi – an amazing software that makes cluster analysis very easy and fun. I wanted to analyze the “unusual” comments in Gephi, but first I had to find a way to represent them as a Network.
In order to do that, I’ve:
- Removed meaningless words such as “and” or “or” (also known as stop words) from every comment using nltk library
- Broke remaining words in every comment into an array (list) of word stems
- For every comment calculated an intersection with every other comment
- Recorder a score for every possible intersection
- Removed all intersection with a score of 0.3 or less
- Saved all comments as nodes in Gephi graph and every intersection score as an undirected edge
By now you might be wondering how the intersection score was calculated. You may also wonder what the heck is Gephi graph, but I’ll get to it a bit later.
Calculating Intersection Score
Let say we have two comments
["mark", "love"] # From "Mark, I love you"
# and
["mark", "love", "more"] # From "Mark, I love you more"
Code language: PHP (php)We can find the score as follows:
def findIntersection(first, second):
intersection = set(first) & set(second) # Find a sub set of words that is present in both lists
intersectionLength = len(intersection) # Words both comments have in common
intersectionLength = float(intersectionLength)
wordCount = len(first) + len(second) # Total length of both comments
if wordCount == 0: # Corner case
return 0
else:
return (intersectionLength/wordCount) # Intersection score between two comments
Code language: PHP (php)So for our example above:
- Intersection between two comments is
["mark", "love"]which is 2 words - Total length of both comments is 5 words
- Intersection score is 2/5 = 0.4
Note: I could have used average length of two comments (so (2+3)/2 = 2.5) instead of total length (5), but it would not have made any difference since the score was calculated similarly for all of the comments . So I decided to keep it simple.
Once I had all of intersection calculated I saved all comments in the nodes.csv file, that had the following format:
Id;Label
1;Mark, I love you
I’ve saved all intersection in the edges.csv file, that had the following format:
Source;Target;Weight;Type
1;2;0.4;"Undirected"
Code language: JavaScript (javascript)Analyzing the Network
This was all that was needed to import my data into Gephi as a Network Graph. You can read more about Gephi file formats here and this video provides a good introduction to Gephi and how it can be used.
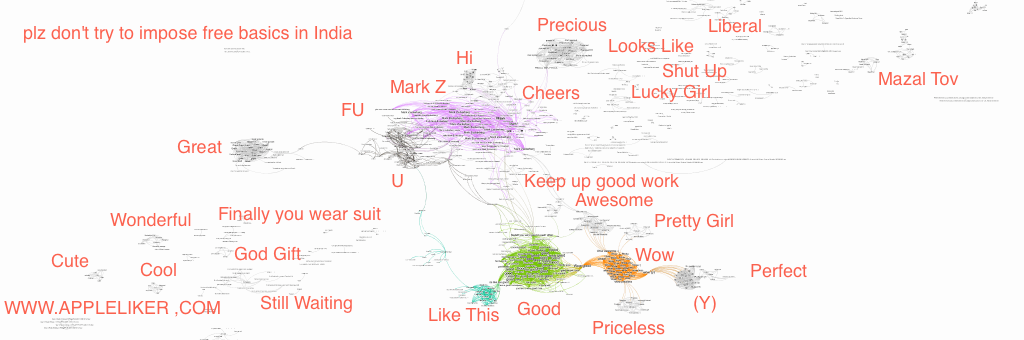
Once I imported my data into Gephi, I’ve run a network analysis algorithm called “Force Atlas 2”, which resulted in the following network Graph.
I’ve manually added the text in red to summarize some of the clusters. If you click on the image, you will be taken to a full screen representation of the graph. It is pretty big, so you might have to zoom out and scroll for a while before you see some data.
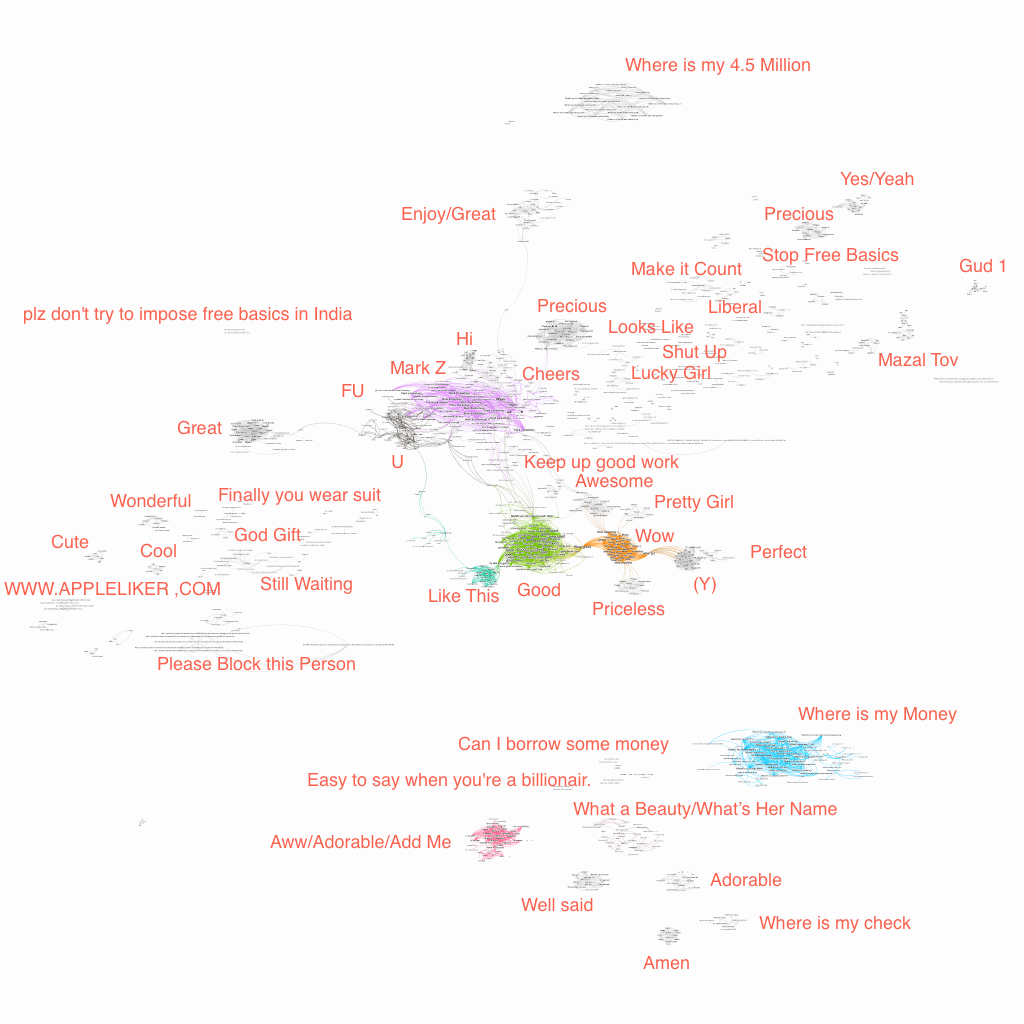
Some Notes on the Results
I was really happy to see my approach finally working (after many days of trying).
I have been starring at those comments for a long time and I’ve seen some references to “money”. Therefore, I was not surprised to see a couple of clusters asking Mark “Where is my Money?”.
I was very surprised, however, to see a cluster of comments mentioning a specific number – 4.5 million to be exact. I had no idea where this number was coming from, but a quick Google search pointed me to this hoax. Turns out a lot of people were duped into believing that Mark would give away 4.5 million to 1000 lucky people. All you had to do was to post a “Thank you” message of sorts.
Other than that, I didn’t see anything very interesting. There were some spammers and some people asking Mark to ban some people form Facebook. Some aggression towards Mark and a lot more of general types of comments that I did not filter out.
I’ve also noticed some weaknesses in my approach. For example, there were two clusters around the word “precious”. It was probably caused by removing relationships that did not have intersection score of at least 0.3. Since I did not use the average length for two comments, the threshold of 0.3 really meant that the two comments were at least 60% similar, and it was probably too high and caused the error. On the flip side it has helped to reduce the number of edges, focusing on the most important connections.
Please let me know in the comments, if you find anything else note worthy or if you have suggestions on how intersection scores can be improved.
Conclusion
It is hard being a celebrity.
I started this journey naively assuming that I can get Mark’s attention by simply posting a comment on his timeline. I did not realize the amount of social media attention an average celebrity gets.
It would probably take a dedicated Data Scientist working full time just to get insight into all of the comments that Mark receives. While Mark can afford to hire such a person, my bet is that he is using his resources for more meaningful things.
That being said, this has been a great learning experience for me. Gephi is a magical tool, and I highly recommend checking it out.
If you want some inspiration for automating things, I highly recommend reading Automate the Boring Stuff with Python.
If you are looking for a good entry level text on Data Science, I found Data Smart to be an informative read, although hard to follow at times.
Also note that I’ve destroyed all of my data sets to comply as best as I can with Facebook’s Terms of Service. Scraping content without permission is also against Facebook’s Terms of Service, but I’ve avoided thinking about it until after I’ve done all of my analysis.
I am hoping that Facebook will over look my transgression, but wanted to make sure I don’t send anybody else down the wrong path without a proper warning.